久しぶりの技術記事です。
今回はKotlinConf 2023のOpening Keynoteでも盛り上がったKotlin Notebookを使い、最近JetBrainsが力を入れていくことを発表したO/RマッパーのExposedを動かすというのをやってみます。
特にKotlin Notebookはまだなかなか触ったことない方も多いと思いますが、便利なのでぜひ試していただければと思います。
Kotlin Notebookとは?
Kotlin Notebookは、KotlinConf 2023で発表されたIntelliJ IDEAのプラグインで、Kotlinでの対話型の実行環境を実現するものになります。
Pythonなどで利用できるJupyter Notebookが有名ですが、それに似た形のUIや機能で利用でき、Kotlinに特化した形でIntelliJ IDEA上で実行できます。
こちらを使うことで様々なKotlinのコード、あるいはライブラリなどを、アプリケーションを作ることなくインタラクティブに動かすことができます。
今回は後述するExposedのサンプルコードを、Kotlin Notebook上で動かしてみます。
注: Kotlin Notebookは有償版のIntelliJ IDEA Ultimateでのみ利用できます
Exposedとは?
Exposedは、JetBrains社が開発しているKotlin製のO/Rマッパーです。
SQLライクに実装できるDSL、軽量なDAOという2つのアクセス方法が用意されているのが特徴として語られます。
このフレームワーク自体はかなり前からあり、主にサーバーサイドの開発者からはずっと期待されていたのですが、バージョン0.x.xの状態が続いていてなかなか正式リリースがされていませんでした。
しかし先日以下の記事がリリースされ、1.0のリリースに向けて進んでいくことが発表されました。
現状でもKotlinを導入している企業では利用しているプロジェクトもありますが、今後はより多くの場所で積極的に活用されていくことが予想されます。
なので今回はKotlin Notebookを使って、Exposedを簡単に動かしてみたいと思います。
Kotlin Notebookのインストール
まずはKotlin Notebookをインストールして動かしてみます
インストール
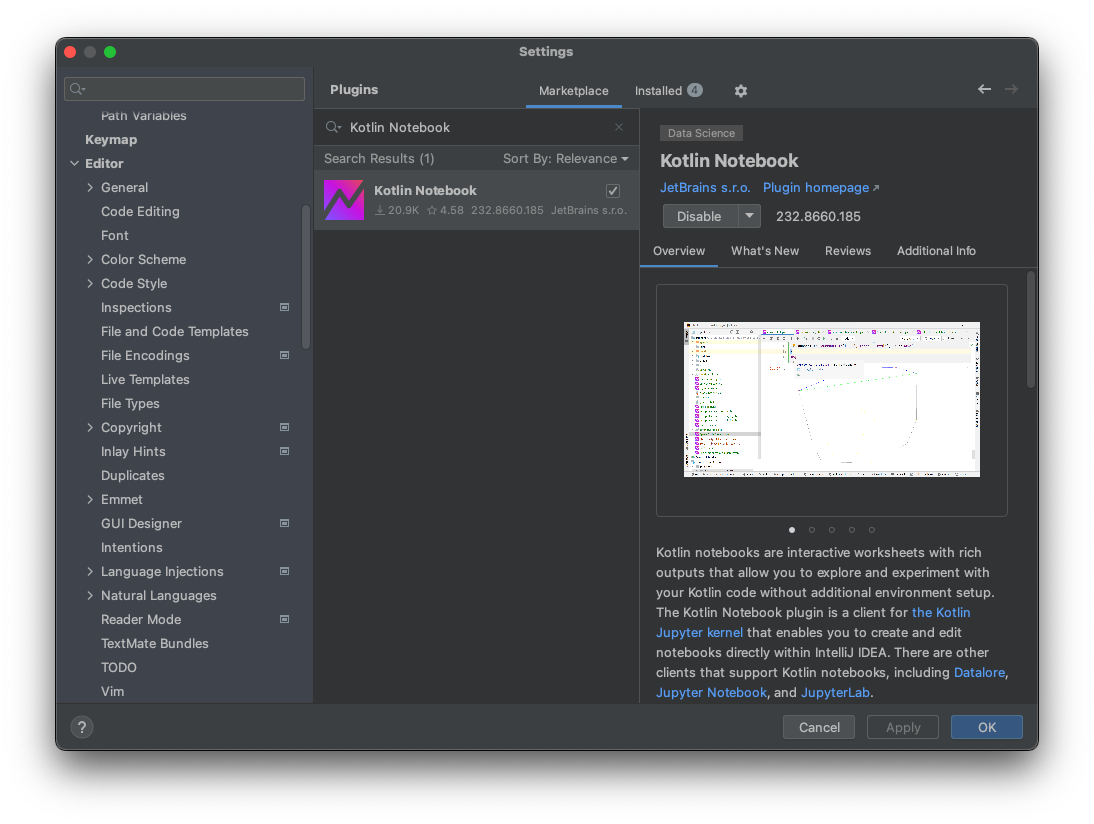
IntelliJ IDEAのメニューでIntelliJ IDEA -> Settings... を開き、「Plugins」を選択します。
「Marketplace」タブで「Kotlin Notebook」と入力して検索すると表示されるので、「Install」ボタンを押してインストールします。
プロジェクト、ファイル作成
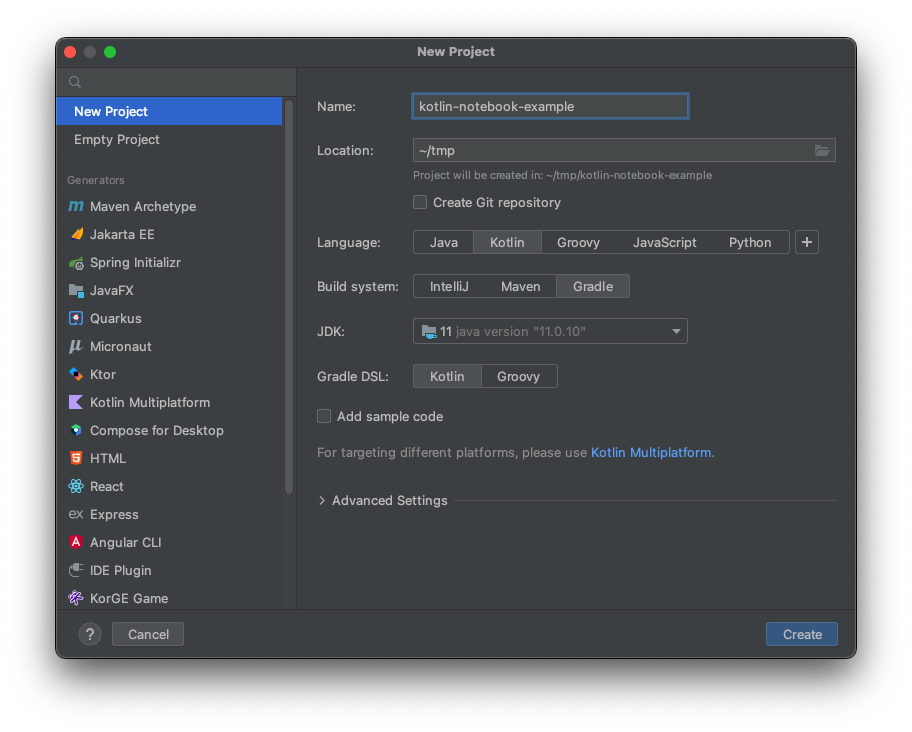
インストールが終わったら、任意のプロジェクトを作成します。
Kotlin Notebook用のプロジェクトなどはなく、以下のような通常のKotlinプロジェクトを作成すれば大丈夫です。
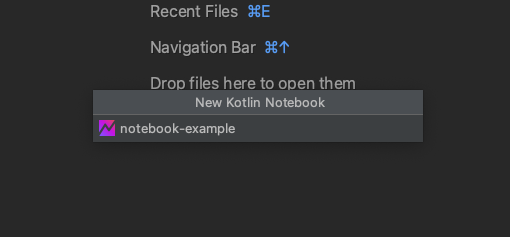
作成したプロジェクトで、任意のディレクトリにKotlin Notebookのファイルを作成します(ここではsrc直下に作成します)。
右クリック -> New のメニューの中に「Kotlin Notebook」が追加されているので、そちらを選択します。

任意の名前を入力し、Enterで.ipynbという拡張子のファイルが作成されます。
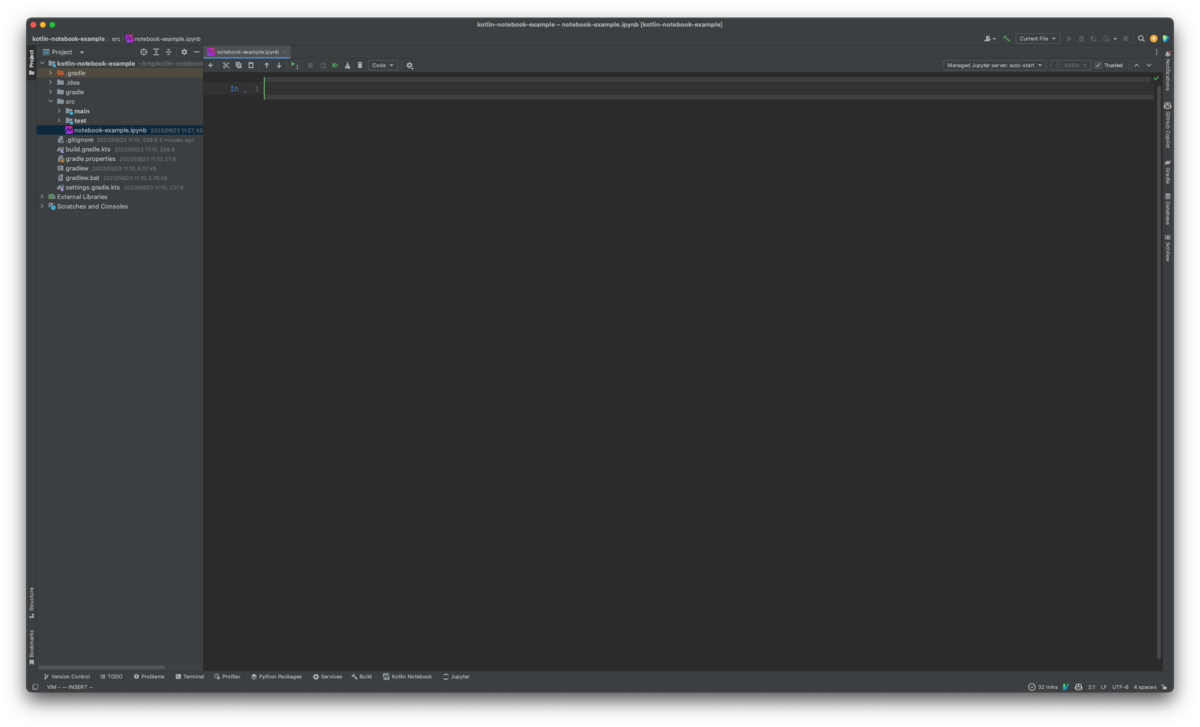
サンプル実行
作成したファイルを開くと、以下のような画面が表示されます。
まず以下のコードを実行してみます。
println("Hello Kotlin Notebook.")
入力して、その行を 右クリック -> Run Cell で実行できます。
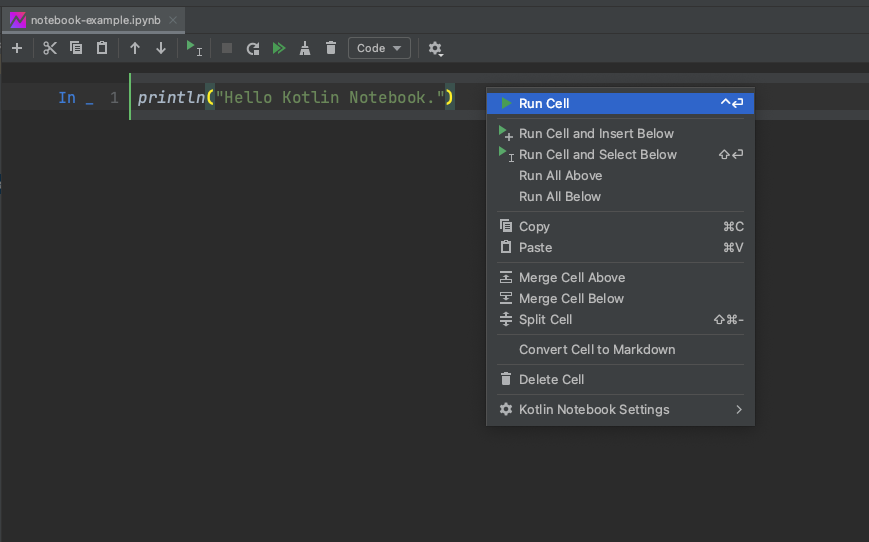
実行すると、以下のように結果が結果が出力されます。

この実行している行は「Cell」という一つの単位で扱われ、以下のように複数行にして実行することも可能です。

Cellの追加
ここからNotebookらしい操作になってくるのですが、Cellは追加して、それぞれ実行することができます。
先程実行したCellで右クリックし、「Run Cell and and Insert Bellow」を選択してください。
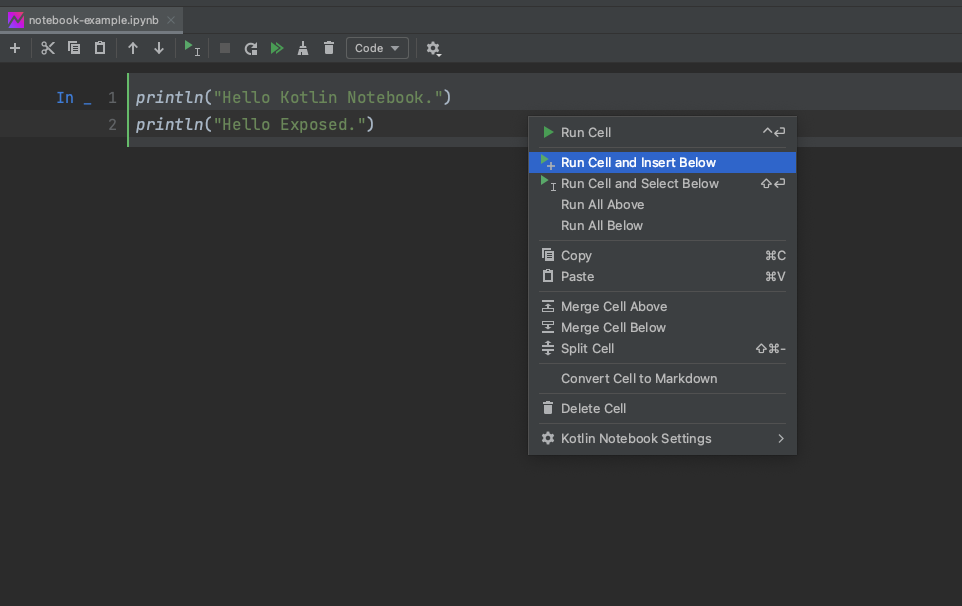
Cellが追加されるので、以下のようにprintln("Insert Cell.")と入力して、このCellで右クリックして実行します。

すると追加したCellのコードだけ実行され、結果が出力されます。
このサンプルではそれぞれ文字列を出力しているだけですが、上のCellの実行結果は引き継ぐことができます。
以下の2つのCellを追加してみましょう。
Cell_1
val randomStr = ('A'..'Z').random()
Cell_2
println(randomStr)

Cell_1ではA〜Zの中からランダムで1文字を返し、変数randomStrに代入しています。
Cell_2ではそのrandomStrを出力しています。
順番に実行すると、Cell_2の実行で以下のようにランダムな1文字が出力されます。

そしてCell_2だけを何回か実行してみてください。
毎回同じ文字が出力されると思います。
これはrandomStrの値はCell_1で実行された結果がそのまま保持されていて、Cell_2は出力されているだけのためです。
今度はCell_1を再度実行し、その後にCell_2を実行してみてください。
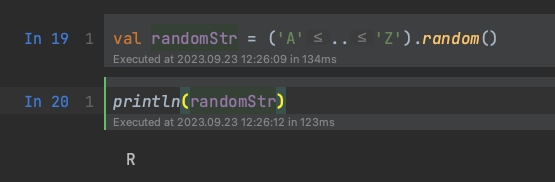
出力結果が変わりました。
randomStrの値が別のランダム値で書き換えられたためです。
このように一定の単位でCellを分けておくことで、部分的に再実行しながら動作を確認してコードを書いけるのが大きな利点です。
ライブラリやAPIの動作検証などをする時にも、少しずつ動かして確認することができるので、効率的に作業することができます。
Exposedを使う
今度はKotlin Notebookを使って、Exposedのサンプルを動かしてみます。
以下のGitHubのREADMEに載っているコードを使っていきます。
Gradleへ依存関係の追加
プロジェクトは前述のKotlin Notebookの実行で使っていたものをそのまま利用して大丈夫です。
gradle.propertiesを開き、以下の1行を追加します。
exposedVersion=0.41.1
Exposedのバージョンを定義しています。
現時点で最新は0.43.0となっておりますが、なぜか動作しないため動くバージョンまで落としています。
そしてbuild.gradle.ktsを開きdependenciesの部分を以下のように書き換えます。
val exposedVersion: String by project // 追加 dependencies { testImplementation(kotlin("test")) // 追加(ここから) implementation("org.jetbrains.exposed:exposed-core:$exposedVersion") implementation("org.jetbrains.exposed:exposed-crypt:$exposedVersion") implementation("org.jetbrains.exposed:exposed-dao:$exposedVersion") implementation("org.jetbrains.exposed:exposed-jdbc:$exposedVersion") implementation("org.jetbrains.exposed:exposed-kotlin-datetime:$exposedVersion") implementation("org.jetbrains.exposed:exposed-money:$exposedVersion") implementation("org.jetbrains.exposed:exposed-spring-boot-starter:$exposedVersion") implementation("com.h2database:h2:2.2.222") implementation("mysql:mysql-connector-java:8.0.33") // 追加(ここまで) }
val exposedVersion: String by projectで前述のgradle.propertiesで定義した値を読み込んでいます。
基本的にはExposedに関する依存関係で、下の2つはDBとして使用するH2 DatabaseとMySQLへ接続するためのライブラリです。
Exposedの公式のExampleを動かす(SQL DSL)
それでは、Exposedを動かしてみます。
READMEにある通り、Exposedは「SQL DSL」「DAO」という2つの実装方法が用意されていますが、今回はSQL DSLの方で動かしてみます。
新しいKotlin Notebookのファイルを作成し、以下の3つのCellを追加してください。
Cell_1
import org.jetbrains.exposed.sql.* import org.jetbrains.exposed.sql.SqlExpressionBuilder.like import org.jetbrains.exposed.sql.transactions.transaction
Cell_2
object Users : Table() { val id: Column<String> = varchar("id", 10) val name: Column<String> = varchar("name", length = 50) val cityId: Column<Int?> = (integer("city_id") references Cities.id).nullable() override val primaryKey = PrimaryKey(id, name = "PK_User_ID") // name is optional here } object Cities : Table() { val id: Column<Int> = integer("id").autoIncrement() val name: Column<String> = varchar("name", 50) override val primaryKey = PrimaryKey(id, name = "PK_Cities_ID") }
Cell_3
Database.connect("jdbc:h2:mem:test", driver = "org.h2.Driver", user = "root", password = "") transaction { addLogger(StdOutSqlLogger) SchemaUtils.create(Cities, Users) val saintPetersburgId = Cities.insert { it[name] = "St. Petersburg" } get Cities.id val munichId = Cities.insert { it[name] = "Munich" } get Cities.id val pragueId = Cities.insert { it.update(name, stringLiteral(" Prague ").trim().substring(1, 2)) }[Cities.id] val pragueName = Cities.select { Cities.id eq pragueId }.single()[Cities.name] println("pragueName = $pragueName") Users.insert { it[id] = "andrey" it[name] = "Andrey" it[Users.cityId] = saintPetersburgId } Users.insert { it[id] = "sergey" it[name] = "Sergey" it[Users.cityId] = munichId } Users.insert { it[id] = "eugene" it[name] = "Eugene" it[Users.cityId] = munichId } Users.insert { it[id] = "alex" it[name] = "Alex" it[Users.cityId] = null } Users.insert { it[id] = "smth" it[name] = "Something" it[Users.cityId] = null } Users.update({ Users.id eq "alex" }) { it[name] = "Alexey" } Users.deleteWhere { Users.name like "%thing" } println("All cities:") for (city in Cities.selectAll()) { println("${city[Cities.id]}: ${city[Cities.name]}") } println("Manual join:") (Users innerJoin Cities) .slice(Users.name, Cities.name) .select { (Users.id.eq("andrey") or Users.name.eq("Sergey")) and Users.id.eq("sergey") and Users.cityId.eq(Cities.id) }.forEach { println("${it[Users.name]} lives in ${it[Cities.name]}") } println("Join with foreign key:") (Users innerJoin Cities) .slice(Users.name, Users.cityId, Cities.name) .select { Cities.name.eq("St. Petersburg") or Users.cityId.isNull() } .forEach { if (it[Users.cityId] != null) { println("${it[Users.name]} lives in ${it[Cities.name]}") } else { println("${it[Users.name]} lives nowhere") } } println("Functions and group by:") ((Cities innerJoin Users) .slice(Cities.name, Users.id.count()) .selectAll() .groupBy(Cities.name) ).forEach { val cityName = it[Cities.name] val userCount = it[Users.id.count()] if (userCount > 0) { println("$userCount user(s) live(s) in $cityName") } else { println("Nobody lives in $cityName") } } SchemaUtils.drop(Users, Cities) }
Cell_1はimport文のみ書いています。
Cell_2はデータベースで扱う各テーブルのデータを扱うオブジェクトで、TableというExposedのクラスを継承し、UsersとCitiesという2つのテーブルを実装しています。
そしてCell_3でCell_2のオブジェクトを使用してデータベースへのクエリを実行しています。(Cell_3はREADME上のコードではmain関数になっている部分ですが、Kotlin Notebookの場合はCell内に書いてあるコード自体をそのまま実行することができるので、main関数を書く必要はありません。)
Cell_2のオブジェクトを使用して、以下のような形で各種操作を実行しています。
// Citiesにinsertしてauto_incrementで生成した主キーの値を返す val munichId = Cities.insert { it[name] = "Munich" } get Cities.id
// idを指定してCitiesのレコードのnameをselect val pragueName = Cities.select { Cities.id eq pragueId }.single()[Cities.name]
// idを指定してUsersの対象のレコードのnameをupdate Users.update({ Users.id eq "alex" }) { it[name] = "Alexey" }
// nameを正規表現で指定しUsersのレコードを削除 Users.deleteWhere { Users.name like "%thing" }
Database.connect("jdbc:h2:mem:test", driver = "org.h2.Driver", user = "root", password = "")
の箇所でデータベースへの接続を行っていますが、ここではH2 Detabaseで全てオンメモリで処理を実行しています。
そのため実行すると以下のようなログが流れて、データはどこにも残らない状態で終了します。
SQL: SELECT SETTING_VALUE FROM INFORMATION_SCHEMA.SETTINGS WHERE SETTING_NAME = 'MODE'
SQL: CREATE TABLE IF NOT EXISTS CITIES (ID INT AUTO_INCREMENT, "NAME" VARCHAR(50) NOT NULL, CONSTRAINT PK_Cities_ID PRIMARY KEY (ID))
SQL: CREATE TABLE IF NOT EXISTS USERS (ID VARCHAR(10), "NAME" VARCHAR(50) NOT NULL, CITY_ID INT NULL, CONSTRAINT PK_User_ID PRIMARY KEY (ID), CONSTRAINT FK_USERS_CITY_ID__ID FOREIGN KEY (CITY_ID) REFERENCES CITIES(ID) ON DELETE RESTRICT ON UPDATE RESTRICT)
SQL: INSERT INTO CITIES ("NAME") VALUES ('St. Petersburg')
SQL: INSERT INTO CITIES ("NAME") VALUES ('Munich')
SQL: INSERT INTO CITIES ("NAME") VALUES (SUBSTRING(TRIM(' Prague '), 1, 2))
SQL: SELECT CITIES.ID, CITIES."NAME" FROM CITIES WHERE CITIES.ID = 3
pragueName = Pr
SQL: INSERT INTO USERS (CITY_ID, ID, "NAME") VALUES (1, 'andrey', 'Andrey')
SQL: INSERT INTO USERS (CITY_ID, ID, "NAME") VALUES (2, 'sergey', 'Sergey')
SQL: INSERT INTO USERS (CITY_ID, ID, "NAME") VALUES (2, 'eugene', 'Eugene')
SQL: INSERT INTO USERS (CITY_ID, ID, "NAME") VALUES (NULL, 'alex', 'Alex')
SQL: INSERT INTO USERS (CITY_ID, ID, "NAME") VALUES (NULL, 'smth', 'Something')
SQL: UPDATE USERS SET "NAME"='Alexey' WHERE USERS.ID = 'alex'
SQL: DELETE FROM USERS WHERE USERS."NAME" LIKE '%thing'
All cities:
SQL: SELECT CITIES.ID, CITIES."NAME" FROM CITIES
1: St. Petersburg
2: Munich
3: Pr
Manual join:
SQL: SELECT USERS."NAME", CITIES."NAME" FROM USERS INNER JOIN CITIES ON CITIES.ID = USERS.CITY_ID WHERE ((USERS.ID = 'andrey') OR (USERS."NAME" = 'Sergey')) AND (USERS.ID = 'sergey') AND (USERS.CITY_ID = CITIES.ID)
Sergey lives in Munich
Join with foreign key:
SQL: SELECT USERS."NAME", USERS.CITY_ID, CITIES."NAME" FROM USERS INNER JOIN CITIES ON CITIES.ID = USERS.CITY_ID WHERE (CITIES."NAME" = 'St. Petersburg') OR (USERS.CITY_ID IS NULL)
Andrey lives in St. Petersburg
Functions and group by:
SQL: SELECT CITIES."NAME", COUNT(USERS.ID) FROM CITIES INNER JOIN USERS ON CITIES.ID = USERS.CITY_ID GROUP BY CITIES."NAME"
2 user(s) live(s) in Munich
1 user(s) live(s) in St. Petersburg
SQL: DROP TABLE IF EXISTS USERS
SQL: DROP TABLE IF EXISTS CITIES
接続先のデータベースをMySQLに変更する
最後に、接続先のデータベースをH2 DatabaseからMySQLへ変更してみます。
以下のコマンドでDockerでMySQLを起動してください(Dockerが入っていない方は、Docker Desktopなどをインストールして起動してから実行してください)。
docker container run --rm -d -e MYSQL_ROOT_PASSWORD=mysql -p 3306:3306 --name mysql mysql
起動したら、接続して「exposed_example」というデータベースを作成してください。
mysql -h 127.0.0.1 --port 3306 -uroot -pmysql
create database exposed_example;
そしてKotlin Notebookで前述のCell_3の
Database.connect("jdbc:h2:mem:test", driver = "org.h2.Driver", user = "root", password = "")
の部分を
Database.connect(
"jdbc:mysql://127.0.0.1:3306/exposed_example",
driver = "com.mysql.jdbc.Driver",
user = "root",
password = "mysql"
)
に書き換えてください。
これで接続先のデータベースが起動したMySQLに変更されます。
また、元のコードでは最後に作成したテーブルをdropしているのですが、実行後の状態が確認できないためCell_3にある以下の行を削除してください。
SchemaUtils.drop(Users, Cities)
そして再びCell_3を実行すると、以下のように実行結果が表示されます。
SQL: CREATE TABLE IF NOT EXISTS Cities (id INT AUTO_INCREMENT, `name` VARCHAR(50) NOT NULL, CONSTRAINT PK_Cities_ID PRIMARY KEY (id))
SQL: CREATE TABLE IF NOT EXISTS Users (id VARCHAR(10), `name` VARCHAR(50) NOT NULL, city_id INT NULL, CONSTRAINT PK_User_ID PRIMARY KEY (id), CONSTRAINT fk_Users_city_id__id FOREIGN KEY (city_id) REFERENCES Cities(id) ON DELETE RESTRICT ON UPDATE RESTRICT)
SQL: INSERT INTO Cities (`name`) VALUES ('St. Petersburg')
SQL: INSERT INTO Cities (`name`) VALUES ('Munich')
SQL: INSERT INTO Cities (`name`) VALUES (SUBSTRING(TRIM(' Prague '), 1, 2))
SQL: SELECT Cities.id, Cities.`name` FROM Cities WHERE Cities.id = 3
pragueName = Pr
SQL: INSERT INTO Users (city_id, id, `name`) VALUES (1, 'andrey', 'Andrey')
SQL: INSERT INTO Users (city_id, id, `name`) VALUES (2, 'sergey', 'Sergey')
SQL: INSERT INTO Users (city_id, id, `name`) VALUES (2, 'eugene', 'Eugene')
SQL: INSERT INTO Users (city_id, id, `name`) VALUES (NULL, 'alex', 'Alex')
SQL: INSERT INTO Users (city_id, id, `name`) VALUES (NULL, 'smth', 'Something')
SQL: UPDATE Users SET `name`='Alexey' WHERE Users.id = 'alex'
SQL: DELETE FROM Users WHERE Users.`name` LIKE '%thing'
All cities:
SQL: SELECT Cities.id, Cities.`name` FROM Cities
1: St. Petersburg
2: Munich
3: Pr
Manual join:
SQL: SELECT Users.`name`, Cities.`name` FROM Users INNER JOIN Cities ON Cities.id = Users.city_id
WHERE ((Users.id = 'andrey') OR (Users.`name` = 'Sergey')) AND (Users.id = 'sergey') AND (Users.city_id = Cities.id)
Sergey lives in Munich
Join with foreign key:
SQL: SELECT Users.`name`, Users.city_id, Cities.`name` FROM Users INNER JOIN Cities ON Cities.id = Users.city_id WHERE (Cities.`name` = 'St. Petersburg') OR (Users.city_id IS NULL)
Andrey lives in St. Petersburg
Functions and group by:
SQL: SELECT Cities.`name`, COUNT(Users.id) FROM Cities INNER JOIN Users ON Cities.id = Users.city_id GROUP BY Cities.`name`
1 user(s) live(s) in St. Petersburg
2 user(s) live(s) in Munich
前述のH2 Databaseで実行した時の結果から、最後のDROP TABLEの部分だけ減っています。
そして再びMySQLに接続し、exposed_exampleの中を参照すると、テーブルが作成されレコードが登録されているのがわかります。
mysql> show tables; +---------------------------+ | Tables_in_exposed_example | +---------------------------+ | Cities | | Users | +---------------------------+
mysql> select * from Cities; +----+----------------+ | id | name | +----+----------------+ | 1 | St. Petersburg | | 2 | Munich | | 3 | Pr | +----+----------------+
mysql> select * from Users; +--------+--------+---------+ | id | name | city_id | +--------+--------+---------+ | alex | Alexey | NULL | | andrey | Andrey | 1 | | eugene | Eugene | 2 | | sergey | Sergey | 2 | +--------+--------+---------+
Kotlin Notebookで色々試してみましょう
今回はKotlin Notebookを使って、ExposedのGitHubに載っているExampleを動かしてみました。
このようにフレームワークやライブラリを試しに動かしてみる時にも、手軽に使えてとても便利です。
有償版でしか使えないのは難点ですが、使える方は他のコードも色々動かして、自分の使いたいものの検証などにぜひ活用していただければと思います。